During the course Design of Dynamic Web Systems, M7011E at Luleå University of Technoloy, me and another classmate designed and developed a dynamic web system. The project contained both a web server and a dynamic Single Page Application (SPA) front-end. The web server was written in Go from scratch using only the Gorilla libraries for simplifying some parts of the routing. By writing most of the lower level web server logic, such as CSRF token handling, we learned a lot about web server development and the security practices of modern web applications.
Furthermore, the front-end was written in TypeScript together with Mitrhil.js. We had never worked with both in the same project before, it proved to be a challenge where we had to implement our own project structure that would fit them both. The structure is centered around view-controller components similar to that of React. Mithril.js uses a Virtual DOM (VDOM) where all the views are defined as TypeScript instead of HTML. As an experiment we decided to also define the CSS in the same source files, but as simple variables that can be injected using Mithril.js’ style attribute.
The web site is currently available at: https://roast.software, so pay a quick visit and play around with it!
Below follows the whole project report with all our design decisions and lessons learned through out the project. Enjoy!
The source code is available at: https://github.com/RoastSoftware/roaster.
The PDF document for the full report: https://github.com/optmzr/m7011e-project-roaster-report/releases/download/v1.0.0/M7011E_Project_Roaster_Report_wenwil_5_phihjo_2.pdf
Note: The whole report is converted from LaTex using Pandoc, so you might find some oddities.
The problem
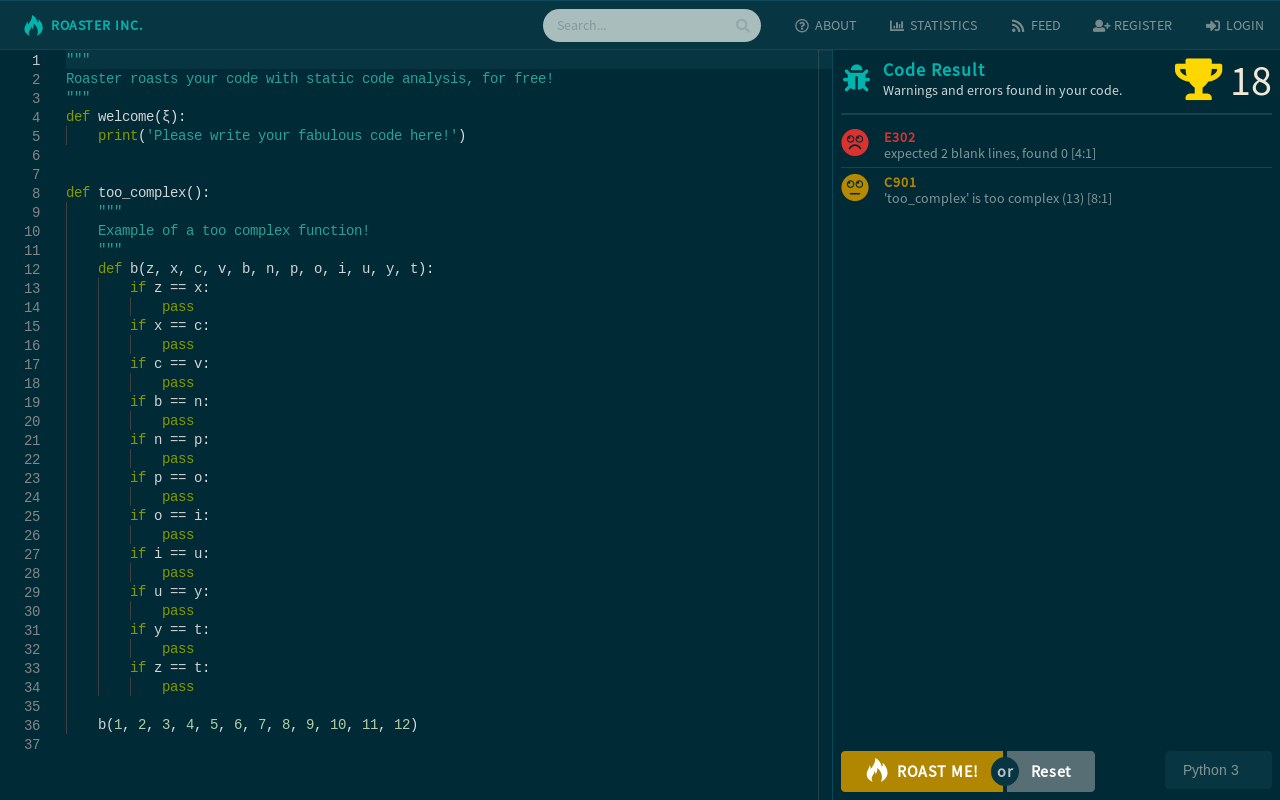
One of the big pains when programming in groups is code that is unreadable. Many times you can look at a code snippet and see who wrote that piece just based on the formatting and comments. The solution to this is to enforce an uniform code and documentation style that every person adheres to. This is normally done by installing a linting tool chain and configuring it equally on all systems used for developing. The idea for this project is to eliminate the installing and configuring step by doing it all with the site called Roaster Inc. (https://roast.software), along with the intriguing feature of following your own and friends code quality progress.
Roaster analyzes and grades your code. The user can register and follow their personal programming progress and compare it with people they follow - you could compare it to music scrobbling, but for code! Personal statistics is generated by running static code analysis on the uploaded code - data such as number of errors, number of warnings and even code style problems is collected. The statistics can then be viewed in a feed where both your own and the people you follows progress is listed. Global statistics like number of errors and warnings and number of rows analyzed is displayed on a page that can be viewed by everyone.
A typical user scenario could be that a teacher is sick and tired of reading spaghetti code made by novice students and would rather let them learn that readability and an uniform code style is important. But that takes time to teach, and the teacher has to focus on the actual subject of the course.
Instead, the teacher can tell the students that they have to Roast their code and get no warnings and errors before submitting the work!
The students increases their code quality and the teachers are happier!
Technology choices
The participants of the course were encouraged to learn new technologies and tools that the developers had never used before or wanted to learn more about. The technologies chosen all was chosen with scalability and security in mind, whenever applicable the developers chose enterprise grade software.
Database
In order to choose the right database for a project the designers need to consider what type of data that is to be stored and if availability (NoSQL) or robustness (SQL) is of utmost importance. Considering the aspects above the developers chose robustness, a SQL database should be the best choice for this type of application where mainly structured data is stored.
While designing the system, the developers wanted the database to handle objects with strict value types (domains), hence a Object Relational Database (ORD) was desired and PostgreSQL has good support for advanced features for object handling and custom definition of objects. PostgreSQL is also fully ACID compliant[@pg-acid] which is desired. PostgreSQL has the ability to use advanced data constraints which enables better robustness. PostgreSQL also has good conformance with the SQL standard[@pg-sql-conformance]. PostgreSQL is one of the most advanced and fastest databases[@db-benchmark] that is free to use and open source. One of the two developers in this project had prior experience with PostgreSQL but only shallow knowledge which also made it interesting as a technology to learn more about.
One of the advanced features PostgreSQL has is its HSTORE, the ability to store sets of key/value pairs within a single PostgreSQL value[@pg-hstore], comparable to an hash table. During the design phase the developers thought this feature would be good to have when storing the messages1 but as it turns out, it was not necessary, as explained in .
Competing technologies that we discarded due to the following drawbacks.
MySQL ignores
CHECKconstraints[@mysql-check-constraint], requires writing advanced triggers to emulateCHECKinstead[@mysql-emulate-check].SQLite is primarily for embedded systems or low to medium volume websites and doesn’t scale[@sqlite-when-to-use].
MariaDB doesn’t offer the same amount of data integrity out of the box as
PostgreSQL[@mariadb-data-integrity], up to the user to implement it correctly.
Session store
A shared session store allows the web server to scale up and down with instances and still have access to the same session store as the other instances.
To save and retrieve sessions in a speedy fashion a fast in memory key/value database is used. The choice is Redis, an advanced software made for horizontal scaling by clustering. It’s superior to Memcached in key names, whereas Memcached only supports 250 bytes of plain strings[@memcache-key-size], Redis handles key/values to be as big as 512 MB[@redis-key-size] and any kind of binary data. Redis is also more modern and up to date which makes it more popular and a more relevant technology to learn[@key-value-comparison][@redis-vs-memcached].
Containerized web server
Docker[@why-docker] is not required to run the web server, it is able to run in both Linux and Windows host environments. AWS also support running the web server on “bare metal", but was deemed to hard and time consuming to setup as the developers had no experience with this since before. Instead Docker is used to create a minimal environment that is capable of running the web server on AWS.
The Docker containers are also run in the CI/CD2 Travis CI pipeline before the actual deployment to AWS to ensure that the images work correctly. Docker offered a great experience when it comes to the deployment. Due to the testing of the images before deployment no compile errors was encountered when deploying to the live environment.
Docker also offered a great experience during the development on the developers local machines. Development took place on both a Windows and a Gentoo Linux machine so to make the setup of the databases easier they were run using Docker containers.
Go web server
To acquire more in depth knowledge of a web servers inner workings we chose to write the server without a framework. The language of choice is the Go language (hereby referred to as only Go) since it has a solid foundation as a web server language and that one of the developers had some prior experience with writing a HTTP web server with just the standard net/http package. To facilitate somewhat faster development and to not have to do everything from scratch the developers chose to use an existing URL router built in Go, called gorilla/mux. The Go language also has good support for connecting to SQL databases through their standard database/sql library, such as PostgreSQL using the pq driver[@go-pq-driver].
Hosting platform
To have a good uptime and availability the solution needs to be deployed on a platform that supports these constraints. The developers had the following possibilities:
To host on personal hardware in a student maintained data center called LUDD. This would ensure that enough resources are available for the application since the hardware is decent. Potential downside was the up time, the facility has recently had problems with stability which is a major factor. These statements are purely subjective and based on previous experiences the developers had with servers being shut down without warning due to overloaded electrical infrastructure at the hosting location.
To host on Virtual Machine provided by LUDD, as previously stated the stability is a major factor and therefore not used.
Cloud infrastructure, due to the fact that the authors are students, they had access to various cloud solutions for free and due to that cloud based experience is valued in the market today, the choice was made to implement the solution in the cloud.
Choosing the cloud platform is not easy, determining if you want PaaS, IaaS or some hybrid took a while. In the end it came down to maturity, scalability and where the developers had enough credits to run the solution. Amazon Web Services (AWS) offered a solution called Elastic Beanstalk (EB)[@what-is-eb] which is a hybrid PaaS with automatic scaling which is used as the platform for the application. The web server that runs in a Docker container resides in an AWS EC2 instance that is managed by EB. The databases are hosted in a Amazon Relational Database Service (RDS) which is a SaaS in AWS.
Amazon Elastic Beanstalk also incorporates Amazon Elastic Load Balancing, a managed load balancer, which is what makes scaling really simple when using multiple web servers.
Due to the technology choices being deliberately chosen to be platform independent, a change of cloud provider or move to physical hardware should be a relatively simple task.
Frontend language
The course aims at using state of the art technologies, the developers wanted to explore this in as many aspects as deemed possible. The frontend language had the requirements of being fast, short learning curve, modern and something that they had not yet used. Other aspects that were highly desired were better type safety.
Strictly typed languages like Elm is functional but was discarded due to the learning curve of such a language did not suite the time budget for the project. JavaScript was the second choice since it has many new interesting features since the ES6 release. This would however not fulfill the desire to use a type strict language. TypeScript[@typescript] is a super set of JavaScript and compiles to plain JavaScript, meaning that TypeScript itself is not something that can run in a browser before its compiled. One could use the abstraction of it being JavaScript extended with type hints. This however gives the option to use standard JavaScript if needed but with added type safety and type hints. This is the language of choice for this project.
Frontend framework
The website will not be very big when it comes to number of pages and views, but will have some complexity when it comes to loading, sending data and rendering new dynamic content. The desired outcome of the project is a website that feels fast as well as secure, based on modern technologies. When accessing a website, your browser start by downloading the defined files, and the website will load faster if those files are smaller. Hence we wanted a small framework.
The website could have been written with pure vanilla JavaScript but frameworks most often makes things easier for the developers by not needing to implement advanced components such as frontend router and fast DOM manipulation.
It was decided that fast DOM manipulation (with a virtual DOM), small size and a frontend router was the main requirements. The developers were also interested in learning component oriented development.
Considered technologies was the following:
React.js + Redux router, was a good candidate with a virtual DOM, good community support, component pattern and neither of the developers had written in it before. Down side was the size of React.js together with Redux.
Vue.js also has a virtual DOM, component pattern and good community support, but is big in size.
Angular.js Does not have a virtual DOM and does therefore not qualify for our needs, the developers also had experience with this framework since earlier.
Backbone.js Relies on dependencies such as jQuery, does not use the component pattern that was of interest.
Mithril.js Has a virtual DOM, is small in size and it’s virtual DOM is fastest of the ones listed above, see fig. 2.1. Has a smaller community that the ones listed above.
All the frameworks listed fulfilled the criteria of having typing’s for TypeScript, which are type strict definitions that allows for interacting with the library type safely.
Mithril.js[@mithril-js] was chosen due to its speed, component design pattern and small size. It is also self contained and requires no external dependencies. The developers felt that its small community size was no big problem and could be seen as a challenge.
![Comparison of JavaScript frameworks size and performance[@mithril-speed].](mithril-js-perf.jpg)
Build system
A corner stone in every project is the tool chain, it has to suit the use case and enhance the experience for the developers. A very common tool for managing JavaScript projects is NPM3 which can acts as a build tool as well as package manager. In this scenario it will be used to lint and fix semantic issues found, manage dependencies, build the resulting JavaScript files and pack them with Webpack[@webpack]. NPM allows for freezing dependencies on specific version and also reports vulnerabilities when installing.
Code editor
The code editor was picked with the frontend language in mind. Since TypeScript originates from Microsoft, their web code editor Monaco, was implemented in this language, which led the developers to consider it an easier integration. Apart from previously stated reasons, the Monaco editor (used in Visual Studio Code) has Microsoft Intellisense, syntax highlighting and auto completion among many advanced features. The editor also benefits from using web workers, meaning that it can spawn a separate thread for the editor and not slow down the rest of the page.
The downside of using a hefty editor like this is the size. But by using lazy loading as explained in this problem was mitigated.
Graphing toolkit
To generate graphs, a lightweight and simple tool with good community was premiered. D3.js was originally chosen but was quickly deemed too advanced for the simple visualizations used by the application. Chart.js is a simple, responsive and renders nicely on all platforms due to it using HTML5 canvas for rendering.
Styling toolkit
Styling can be a tedious task if done from scratch with pure CSS, to speed up development one can use a styling framework. The frameworks considered were:
Bootstrap - widely used styling toolkit that both developers had experience with and therefore not chosen as learning something new was a course requirement.
Semantic UI - simple syntax, predefined themes and ability to only load necessary stylesheets and JavaScript files which makes loading fast. This is the chosen framework.
Semantic UI also had support for customization using their semantic-ui-less package, this was used for customizing the search component.
System architecture & design

Infrastructure
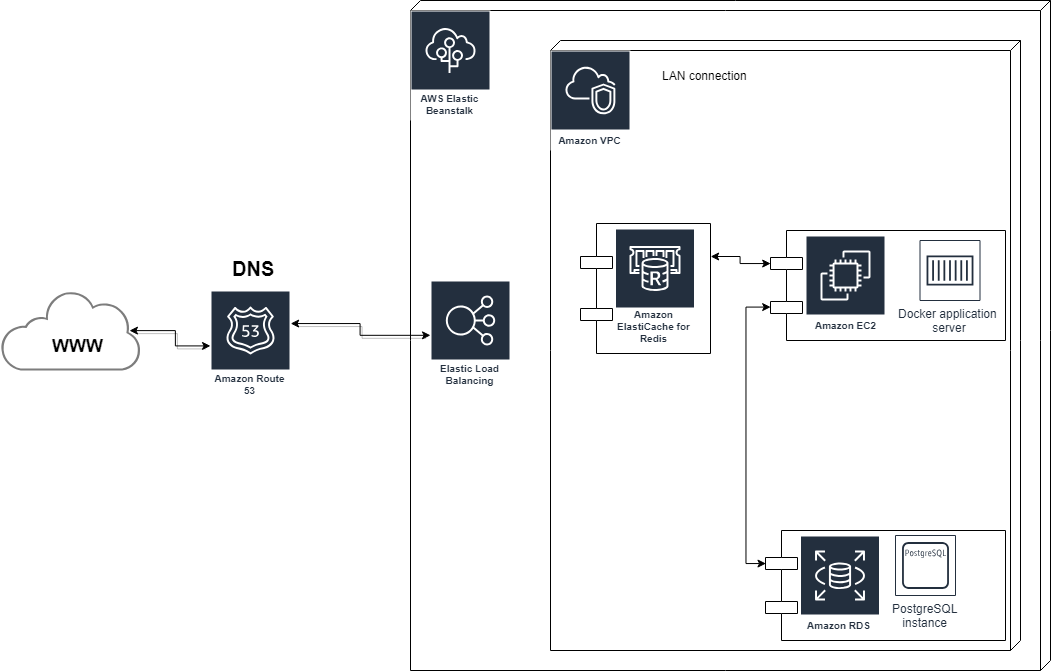
The system is designed to be deployable independently without any dependencies to the underlying platform. This led to containerization of the server in order to facilitate the deployment process and avoid installation mishaps. Both the databases are not containerized as these are run using AWS’ SaaS4 solutions instead.
The whole software architecture is designed to be scalable and is currently running on an Amazon Web Services (AWS) stack. PostgreSQL is used for persistent data storage and can be scaled accordingly depending on the usage requirements. The key store database Redis is used for shared user sessions between several web server instances. Like PostgreSQL, Redis can be scaled with database sharding and has support (through AWS) to run in several regions.
The web server (roasterd) runs in an Elastic Beanstalk (EB) environment that scales the web server automatically depending on the load. AWS uses nginx for load balancing which also provides certificates for HTTPS/TLS. Therefore, the web server behind the load balancer does not use HTTPS/TLS as it was deemed unnecessary.
If the solution is to be deployed at some other hosting solution like your own servers, and scalability is wanted, one would need to setup a load balancer in front of all the web servers. It’s also wise to setup a heavily tested reverse proxy on the load balancer, like nginx. To match the size of your web servers you could also scale the databases.
The communication between the application server and the databases are not encrypted as of now since they are all hosted in a Virtual Private Cloud (VPC) in AWS and thereby sandboxed. VPC also supports encrypted communication internally, but this is not used due to the cost. If implementing this on your own data centre or hardware you have to decide on this yourself in order to secure the architecture. The web server has support for encrypted communication between both databases.
Web application (roasterc)
The web application design structure is based on the MVC5 design pattern. To further isolate the logic the web application uses components, inspired by the pattern used by React[@react-component]. This is in-line with the reactive programming model that the Mithril.js framework is inspired by.
SPA
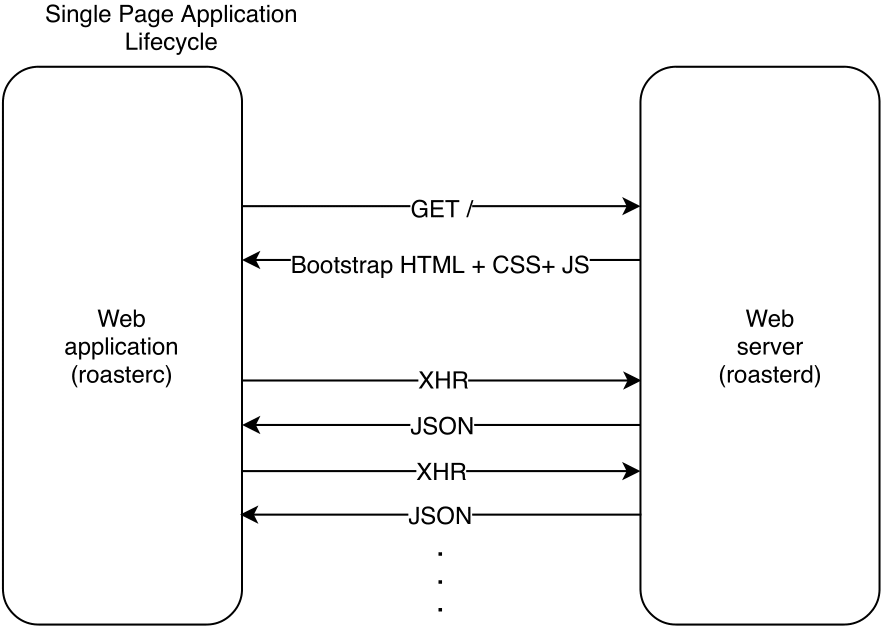
The web application is a single page application (SPA) and is served as a single HTML document at the root (/) of the web server. The HTML document, CSS layouts and JavaScript files that is served through this endpoint bootstraps a client side router that serves each different view of the web application, see fig. 3.1.
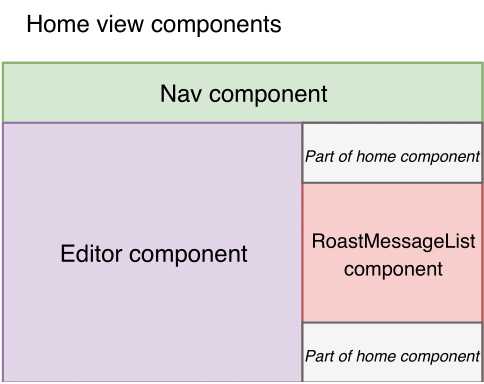
These views are a collection of components each following the MVC pattern, see fig. 3.2. Mithril.js allows the developer to create the views and components with Hyperscript that renders the HTML through the DOM6. The view is generated by diffing the current view with the new one, allowing Mithril.js to only update the relevant parts of the DOM. As a preliminary step to be able to do this fast, Mithril.js creates a Virtual DOM, an internal representation of the DOM that it can work with faster.
Asynchronous communication
All communication that occurs with the web server except for the root endpoint is done RESTfully using the asynchronous XMLHttpRequest (XHR) API that is wrapped by Mithril.js and the web application as Network.request. The wrapping of the XHR API is due to the CSRF mitigation7. Mithril.js will through this wrapper notify the Virtual DOM that it has to be updated after the network request has succeeded (or failed).
Lazy loading
The Monaco editor is used for code submission. It features code completion, highlighting and code mini maps. Even though large parts of the logic is handled in large web workers that runs in separate threads the main JavaScript file that is required is large. For a better user experience where a loading spinner is shown instead of a flickering HTML document it was decided that lazy loading of the editor was needed.
Therefore the Monaco editor is not linked with the initial HTML document. Instead, using Webpacks supports for using the require() / import call, the editor is loaded asynchronously and shown first when it has initialized the main components.
Web server (roasterd)
Code reference/documentation for the roasterd web server (written in Go) can be found here: https://godoc.org/github.com/LuleaUniversityOfTechnology/2018-project-roaster.
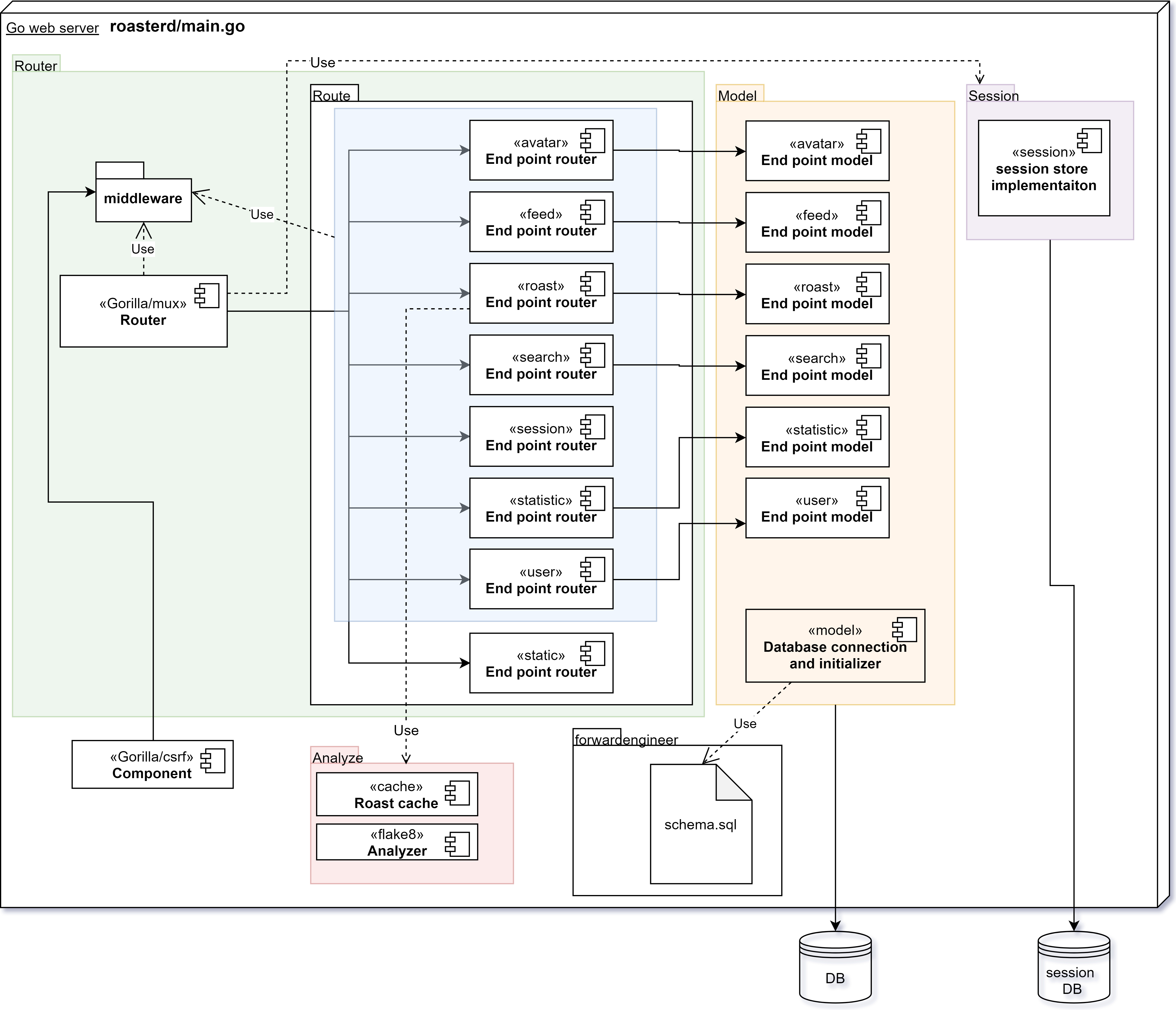
HTTP and routing

Like the web application the web server is also based on the MVC design pattern. The generic handling of HTTP such as CSRF mitigation, Content-Type checking and CORS policies are implemented according to the middleware pattern. The middleware pattern abstracts parts into layers that are coupled together in a pipeline. At the end of the request chain the route handler that adheres to the MVC pattern handles the request and then sends a response that will go through the same middleware pipeline in the reverse direction, see fig. 3.3. The route handlers are defined in the router/route[@roaster-router-route] Go package and represents the controller and view in the MVC model. These route handlers talks to the database via the model that is contained in a separate Go package, called model[@roaster-model].
Analyzing code
Static code analysis is used for grading submitted code. The analyze package implements the methods for each language. Currently only Python 3 is supported using the Flake8 suite and can be accessed through the analyze.WithFlake8(...)[@roasterd-analyze-withflake8] method. Any new languages that are added should provide their own analyze.With... method that follows the same interface as analyze.WithFlake8. The interface is defined as:
func(username, code string) (result *model.RoastResult, err error)Where username and code is the input and result and err is the output of the function.
The result from Flake8 is returned and encoded as JSON by the flake8-json[@flake8-json] formatter. The result is then unmarshalled into an unexported Go struct that follows the same structure as the JSON that flake8-json provides. This unexported struct is then converted into a model.RoastResult that can be saved to the database. The result is then returned to the callee, in this case the /roast route handler.
During development it was discovered that the Flake8 suite was very slow and took several seconds, even for small code snippets. The problem got even worse if a user decided to spam the API with code submissions - the web server would spawn several routines that all analyzed the same code snippet, resulting in a very simple DoS attack. To mitigate the easiest of attacks, and also increase the user experience with faster results, a simple cache was developed.
The cache can be found in the analyze/cache[@roasterd-cache] package and uses expiration and random replacement when it’s filled.
Database
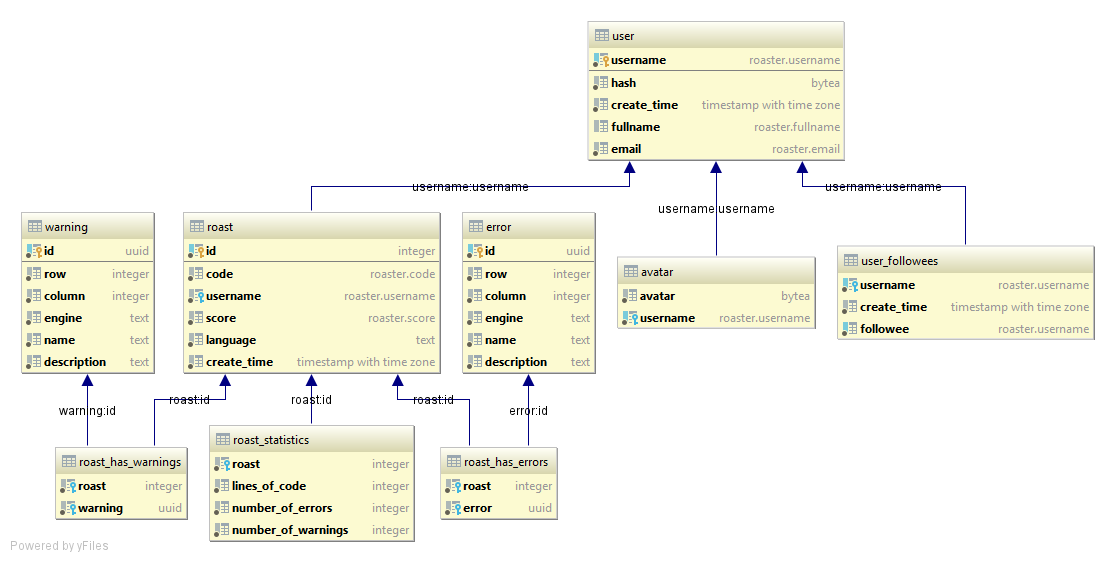
PostgreSQL domains are utilized for validating the data stored in columns. This can be seen in fig. 3.4 where the username column is of the type roaster.username. This custom domain data type will ensure that not any forbidden characters are in the usernames and that their length is atleast 3 characters and below 255. Similarly there are several other domains defined, such as roaster.code, roaster.fullname and roaster.email. The definitions for these domains can be found in doc/postgresql/roaster-database-v0.0.2.sql[@sql-def-line6].
The same file also contains the whole definition of the SQL database used. This file is parsed by a program that can be found in cmd/inlinesql[@roasterd-cmd-inlinesql]. The program will copy each SQL statement into a Go slice (a type of array in Go) that can be used when the web server starts to bootstrap the database with the correct schema setup, this process is also known as forward engineering.
[sec:database-messages] The messages (errors and warnings for code submissions) are stored in separate tables using an UUID based on the content of the message as an identifier and primary key to prevent data duplication. Each message is then referenced by each submission result using a many-to-many relationship, e.g. between the warning table and roast table there is a table, roast_has_warnings that references each other. UUID is also supported as a data type in PostgreSQL[@pg-uuid] allowing for validating the UUID using their built-in constraints.
All user input from the API, except passwords, are validated against the database using its constraints instead of validating the data inside the web server’s route handlers or model. This ensures that the actual data model is defined in one place and not spread out through out the application.
API
The documentation for the Roaster REST API can be found at:
https://roast.software/doc/restapi.
The Roaster API is designed to adhere to the REST principles and at the same time be secure and support user sessions. A trade off has to be made for the requirement of being stateless in REST[@fielding-rest] where both the CSRF mitigation8 and user session requires some state that is kept on the server-side. All API endpoints follow CRUD9 where the HTTP methods are used to represent each part, in the case of the Roaster API the following rules has been decided:
Create -
POSTRead -
GET / HEADUpdate -
PATCH / PUTDelete -
DELETE
The PUT method is used when a resource is overridden, such as when uploading a new profile picture. While the PATCH method is used when the request have the feature of replacing partial data, such as when updating partial user profile information. POST is used when a new resource should be created, such as a new code submission. The DELETE method is used for e.g. removing an user that you are following. The GET and HEAD method should never modify any data.
The Roaster API tries to use clean and logical URI components. The structure uses URI components as categories that are routed to sub-routers in the backend. An example is the /user route, which has several endpoints such as
/user/{username}- User profile information handling for {username},/user/{username}/avatar- Change or retrieve profile picture for {username},/user/{username}/followers- Retrieve a list of followers for {username}.
Where the /user sub-router dispatches different handlers depending on the last URI component (e.g. /avatar or /followers) together with the username as a parameter. In the case of /user/{username} the sub-router sees the last URI component as /.
The HTTP status codes are used to denote both different successful states and error states. The 200 - OK code is returned if the request was successful and there is data to return. While 204 - No Content is used when there is no data to return, e.g. after updating a profile picture or when the user has no followers. The status codes can be found in the REST API documentation mentioned above.
Grade system
There are two different simple measurements for the submitted code, Roast Score and Roast Ratio.
The Roast Score is calculated per code submission and is defined as follows: \[\text{Roast Score} = \left\lfloor\frac{L}{0,8E + 0,29W + 1}\right\rceil\] Where \(L\) is the number of lines of code and \(E\) and \(W\) is the number of errors and warnings, respectively. The cost set for an error is \(0,8\) and \(0,2\) for a warning, so for every line of code \(0,8\) points is removed if it’s an error and \(0,2\) is removed if it’s a warning. So a line with both an error and a warning is worth \(0\) points. The resulting score is rounded to the nearest integer. The Roast Score can never be less than \(0\).
The Roast Ratiocan be calculated for both single submissions or all, it’s defined as: \[\text{Roast Score} = \left\lfloor 1 - \frac{E + W}{S} * 100 \right\rceil\] Where \(S\) is the number of successful lines, i.e. line without any errors or warnings. \(E\) and \(W\) is as previous the number of errors and warnings. The Roast Ratioformula will return a percentage where \(100 \%\) is the best possible ratio.
API
The Roaster API v0.0.1 is fully documented and can be viewed at the following address: https://roast.software/doc/restapi/. The API tries to adhere to the REST principles and is designed around the CRUD pattern, see for more information.
Bootstrap with CSRF mitigation
All API endpoints are protected with CSRF mitigation, except for GET, HEAD, OPTIONS and TRACE (non-write operations). Therefore before doing write operations such as POST and PUT the X-CSRF-Token has to be retrieved. Even if GET isn’t protected with CSRF mitigation the web server will respond with a fresh X-CSRF-Token that can be used for doing a write operation.
A simple HEAD request to the / endpoint will give all the headers that the web server would respond with for a GET request. This is utilized to only retrieve the required token and not the whole web application that it would normally do.
In the following example cURL is used to demonstrate the bootstrapping process.
First, retrieve the X-CSRF-Token header and the CSRF challenge cookie with:
curl -c cookies.txt --head https://roast.software/ \
| grep -Fi x-csrf-token > token.txtWhere cookies.txt contains the cookies and token.txt contains the next X-CSRF-Token. The cookies.txt and token.txt files can be read by specifying -b cookies.txt -H @token.txt as arguments to cURL.
For any following request that is a write operation the cookies and token has to be sent by the client, for a POST /roast the command would be:
# -i - Include response headers in output.
# -b cookies.txt - Read the cookies (incl. challenge).
# -c cookies.txt - Write the new cookies (incl. challenge).
# -H @token.txt - Read token.
curl \
-b cookies.txt \
-c cookies.txt \
-H @token.txt \
-H "Content-Type: application/json" \
-X POST https://roast.software/roast -d \
"{ \
\"language\": \"python3\", \
\"code\": \"print('Hello, world!')\" \
}"Authenticate an user
Because the authentication towards the API is a POST request the CSRF mitigation has to be bootstrapped as explained in . After the bootstrapping has been done the following API request will authenticate a user and save the resulting session cookie:
curl \
-b cookies.txt \
-c cookies.txt \
-H @token.txt \
-H "Content-Type: application/json" \
-X POST https://roast.software/session -d \
"{ \
\"username\": \"willeponken\", \
\"password\": \"my_very_secure_password\" \
}"Now any endpoint that requires a session can be queried, e.g. modifying the user profile information:
curl \
-b cookies.txt \
-c cookies.txt \
-H @token.txt \
-H "Content-Type: application/json" \
-X PATCH https://roast.software/session -d \
"{ \
\"email\": \"[email protected]\", \
\"fullname\": \"William von Willeponken\" \
}"Security considerations
Several security issues has been taken into consideration when developing the system. The OWASP Top 10 list[@owasp-top-10] has acted as a reference during the project to decide what security problems to prioritize and look for.
HTTPS/TLS
The connection from the client to the web server is made over TLS with a Amazon signed certificate. This is configured by the Elastic Load Balancer running on Elastic Beanstalk that acts like a reverse proxy. The request then propagates through the VPC (Virtual Private Cloud) in AWS in plaintext.
Injection
Injection was the top security vulnerability in OWASP Top 10 list[@owasp-top-10]. For Roaster this includes SQL and OS injections. Go’s database/sql library enforces SQL parameterization per default with placeholder parameters[@go-database-sql], ensuring that SQL injections are not possible, as the values are binary safe. OS injections could be an issue due to that the analyzis of code is passed to a separate OS level process (in this case the Python 3 application Flake8). This issue is solved by not allowing any change of the actual command that gets passed to the OS - it’s hard coded and only allows for input through a Linux pipe. Flake8 also does not execute any of the code that it analyzes as the program only uses static code analysis[@pyflakes][@mccabe][@pycodestyle].
CSRF
The site has implemented protection against CSRF (Cross Site Request Forgery). CSRF is a man-in-the-middle attack where the automatic cookie submission10 is abused. A site that utilizes cross-origin requests cannot use the site-only attribute for cookies, i.e. another malicious website open in another tab can also issue authenticated requests to the web service[@rick]. The CSRF security risk was downgraded on the OWASP Top 10 because most frameworks implement and enforce mitigations per default[@owasp-top-10], but because the system is written without any framework this has to be implemented manually.
In order to increase the security against CSRF attacks a rolling random token scheme was chosen and implemented. The rolling scheme ensures that the CSRF token is not stolen as demonstrated by the BREACH attack[@breach]. First, a CSRF cookie is issued by the web server to sign challenges against, then a challenge is issued by the web server as a HTTP header called X-CSRF-Token for every request.
A custom network handling system had to be implemented that wraps XHR requests in the frontend due to the CSRF mitigation system. The library that has been implemented, called Network[@roaster-network], wraps the Mithril.js m.request method and retrieves the new X-CSRF-Token header for every requests and then saves it so it can be used for the next XHR request.
All HTTP methods, except GET, HEAD, OPTIONS and TRACE, that are sent to the web server are required to authenticate with the CSRF challenge response mechanism. Therefore the Network library creates a HEAD request toward the / (root) API endpoint to receive the first initial X-CSRF-Token for the rolling scheme.
Cookie security that can mitigate XSS attacks is discussed below in .
XSS
The Mithril.js framework will automatically escape all HTML tag characters before inserting into the Virtual DOM that it creates[@mithril-trust]. Therefore most XSS (Cross Site Scripting) issues are mitigated. However, because jQuery is used for the search component extra caution has to be taken. The jQuery Search plugin does not escape HTML tag characters so in this case the escaping has to be done explicitly.
Removing the jQuery dependency is discussed in .
Cookie security that can mitigate XSS attacks is discussed below in .
Secure cookies
User session cookies is stored in the cookie store in the browser. These are validated with the HMAC verification mechanism and encrypted with AES-256. HMAC verification ensures that the cookie content has not been tampered with during the transfer[@fips-198]. While AES-256 encrypts the data contained within the cookie, ensuring that no one can read it[@fips-197]. Even with TLS these are real issues due to the BREACH/CRIME vulnerability that is able to extract the HTTP headers for encrypted transfers[@breach]. The BREACH attack is mitigated using the rolling CSRF token scheme explained in .
The session cookies has the HttpOnly attribute enabled which sandboxes the cookie so it cannot be accessed by JavaScript. This will mitigate the most common XSS attacks[@owasp-httponly]. Additionally the sameSite attribute is set to Strict which tells the browser that it should not send the cookie with cross-site requests[@owasp-samesite]. The sameSite attribute will mitigate CSRF attacks, but is only supported in modern browsers. As of August 2018 only \(68,92 \%\) of the browsers used by Internet users supports the sameSite attribute[@owasp-samesite-support]. It was concluded that this low adoption is reason enough to implement the rolling CSRF token scheme described above.
Password storage
There are a lot of challenges keeping user credentials secured. The solution that was chosen is based on well known algorithms, Bcrypt and SHA-512. The implementation uses official libraries in Go, the language in which the server is written.
The plaintext password that is provided by the user will first be transformed to a hash sum with SHA-512. This is due to that Bcrypt limits the input to 72 bytes. By hashing the password with SHA-512 more entropy of the original password is kept. Also, some implementations of Bcrypt that allows for longer passwords can be vulnerable to DoS attacks[@bcrypt-length].
The SHA-512 hash sum is then hashed again using Bcrypt. This is because SHA-512 is a fast hash algorithm not made for password hashing. Bcrypt is designed to be slow and hard to speed up using hardware such as FPGAs and ASICs. The work factor is set to 12 which should make the expensive Blowfish setup take \(> 250\) ms11. The Bcrypt algorithm also takes care of salting of the password and prepends it with the resulting hash.
Dropbox has a great article[@dropbox-passwords] on their password hashing scheme which the Roaster scheme shares many similarities with, however, encryption using AES-256 with a global pepper12 is not used. This was deemed overkill by the developers for the use case of this project. Dropbox also encodes their SHA-512 with base 64, which is not needed in the case of Roaster because the hash result can be saved as raw bytes13.
Some implementations of Bcrypt uses a null byte (0x00) to determine the end of the input[@bcrypt-bug], the Go implementations does not have this problem. So there is no need to encode the data as base 64. This is verified using the program that was created for this project in the cmd/testbcrypt source folder.
The approach used by Dropbox where they encode with base \(64\) will generate a \(\approx 88\) byte long key, which is then truncated to \(72\) bytes. This results in a input with \(64^{72}\) possible combinations. The Roaster approach of not encoding the input as base \(64\) results in a \(64\) byte long key14, where there is 256 possible combinations per byte. This results in an input with \(256^{64}\) possible combinations. Therefore the Roaster approach allows for far more possible entropy because \(64^{72} \ll 256^{64}\) (\(\approx 1,2 \times 10^{24}\) times more!).
The amount of possible entropy for both solution is so high that comparing the differences between them two doesn’t really make sense - but the Roaster solution that allows for more entropy also skips the unnecessary base 64 encode step due to the lack of the null byte bug.
The only requirements set for passwords are a minimum length of 8 characters and a maximum of 4096 characters. The reason is that too many password rules, such as requiring specific characters, will lower the available entropy of the password. Also, with too strict requirements the users usually picks easy to guess patterns, like using ! or 1 at the end of the password due to requirements of special characters and numbers[@oauth-nist]. NIST15 publishes guidelines for password handling each year. In addition to the password length requirement they also recommend 2FA16[@nist-passwords]. This is not yet implemented but would be a future improvement of the security.
Discussion
Cloud provider
In hindsight, the team might have chose a different cloud provider due to complexity in the configuration and maintaining of the service. The cost model is elusive which causes unnecessary re-configurations when choosing a too (cost) expensive configuration. The re-configurations wouldn’t be such a problem if it were a more streamlined process and a matter of adjusting a few things in the web interface rather than rebuilding the majority of the environment, which could take hours. The documentation is decent but gives more to ask for when something is not behaving like expected, this made the developers having to resort to unofficial sources for debugging the environment. The logging of the environment could also be better, only outputting logs with scrambled time stamps makes it very hard to read. A cloud provider which offers a simpler service would suffice until the architecture of the site becomes more complex like wanting to run the Python code analyzers as micro services etc.
Mithril.js
Mithril.js has been a challenge to work with, accidentally using the documentation for version 2 of Mithril.js whilst actually using Mithril.js version 1. The documentation available is also sparse and not very exhaustive. The community is still small compared to the framework giants like React.js, Angular.js and Vue.js which makes finding good examples that describe advanced maneuvers a lot harder. The source code also has a high grade of coupling that makes modifications to it’s inner workings problematic. As an example the developers wanted to extract the CSRF token on XHR responses, but m.request that was provided by Mithril.js skipped the JSON parsing and error handling if the developer provided their own extract function. Due to the too high coupling in the Mithril.js implementation it was not possible to re-use their own logic and the developers had to re-implement the same functionality themselves.
The design pattern with components that is enforced by the framework was clearly document when writing untyped JavaScript code. However, the examples for writing the same code with typed TypeScript was either missing or was written in an experimental style that the authors of the framework tried. This led the developers to also try several different code styles during the project. Several of these style can still be found in the project, some with lower readability. The developers are still unsure what style to use, but no matter what, a re-factoring of several components, views and models is required.
Semantic UI
With the experiences gained from Semantic UI, the developers are not so sure they would use it again. This is mainly due to the dependency on jQuery for certain common features like the search bar. jQuery as a technology does not escape HTML per default[@jquery-sucks] and will introduce a whole new plethora of attack vectors for injection and scripting attacks. Everything that can be done with jQuery can also be accomplished with JavaScript/TypeScript and is therefore considered an unnecessary risk by the developers.
If the project site were to be re-designed, then the developers would most probably choose another CSS framework like Materialize, Milligram or Foundation depending on what would be prioritized in the next version of the site. Materialize[@materialize] for a fast remake, Milligram[@milligram] for mobile focused design and Foundation[@foundation] for an uncompromising design which can offer Graphics Proccessing Unit accelerated animations, and mobile specific elements for fast experience on a mobile device.
Editor
The Monaco editor was chosen partly because of it being written in TypeScript and was thought to ease integration into the web application. One of the serious alternatives was the CodeMirror editor[@codemirror], but was at the time of choosing technologies, not written in TypeScript. During the time of developing Roaster CodeMirror has gone through a rewrite and there is now an unreleased version based on TypeScript[@codemirror-ts]. One of the goals of the site was to make it feel fast and responsive, once loaded the site achieves these goals with flying colors but the developers would in hindsight prefer a smaller editor with less features. Many features used in Monaco are left disabled, such as the mini map.
Another alternative than moving to CodeMirror would be to optimize the Webpack compilation so the Monaco editor would be better separated into smaller JavaScript chunks. Some optimization has already been done, but there is a possibility that it can be improved further.
Future work
The proof of concept is finished for Roaster and the service works as we wanted, but there are several ways to extend the service and improve it. Below follows some larger changes that could extend Roaster. Additionally the current issues that should be solved before extending Roaster is presented in .
More languages
One of the more obvious improvements is to add more languages than Python 3. A simple start would be to add Python 2.7. An interface for each language’s static analyze toolkit has to be implemented that can fulfill the analyze/... package’s generic RoastResult interface. Adding other languages than Python should be easy, but requires that a new toolchain and environment is setup for that specific language on the same system as the web service is running.
Microservices
To ensure that the service can scale as it grows the analyze system could be split into separate microservices for every language. Even in its current implementation a cache is required due to the slowness of the static analysis tools. Microservices would greatly reduce the load on the main web services. The microservice would communicate using a message queuing system, e.g. RabbitMQ, where the main web services can publish a new request and get a response later from one of the microservices. These microservices would be easy to scale for user demand.
Statistics
The presentation and collection of statistics could need more work so that more relevant statistics is presented to the user. An easy start would be statistics for the type of errors and warnings - the data already exists in the backend but is not compiled together for easy parsing through the REST API.
CLI & IDE integration
One feature that the developers had in mind from the start was integrating the system with a CLI tool and IDE’s. Developers could hook their development environment with a CLI that will automatically send their code, on save or commit, to Roaster using its REST API. The API is already built to be easy to integrate with and it should be trivial to create a simple CLI tool. Integrating Roaster with IDE’s would allow the score and statistics to be displayed directly inside the IDE, and at the same time allow for the coders friends to view their progress through the Roaster web interface.
Refactor frontend components
As mentioned in the discussion a refactoring of the components is required for some components in the frontend source. There is no clear set code style that has been chosen by the developers and this would require further pre-studying before refactoring.
Enhanced security
Currently only passwords are supported as authentication. One improvement would be 2FA, Two Factor Authentication, this is recommended by NIST in their password handling
guidelines[@nist-passwords]. There are many other security measures that could be implemented that is mentioned in the guidelines. A Show Password button and password blacklisting are two simple improvements mentioned[@oauth-nist].
Issue tracker
F Requires frontend changes.
B Requires backend changes.
Enhancements
Remove jQueryF
jQuery is used for the search feature and was added due to time constraints, in the future the search component can be implemented with Mithril.js and the jQuery dependency can be removed, thus removing the overhead of having to mitigate XSS injections for non-Mithril.js components.
Tracked in issue: #225
Refactor UserModelF
The logged in user’s data is saved in the static UserModel model. It would be better to have a object that is passed to the views that require them (composition), this would allow for merging the Profile and User views for more DRY[@dry] code. Additionally the request methods should be moved into the model to prevent code duplication. The statistics models are already implemented like this and can be used as inspiration.
Tracked in issue: #184
Use LESS instead of overriding CSS through Mithril.jsF
The Semantic UI styling framework is used for most of the styling of the views. In some cases the definitions by Semantic UI is overrided inline through Mithril.js. Later during the project the semantic-ui-less package was pulled in and integrated with the Webpack build environment. Most of the inline CSS definitions can be removed and be defined as LESS that is compiled together with Semantic UI instead.
Tracked in issue: #130
Clean up error handlingF
There is no clear error handling pattern used for the frontend. The situation has gotten better throughout the project but there are still some parts of the code base that do not handle errors in a nice way.
Tracked in issue: #115
Features
View specific Roast resultF+B
After a user has been Roasted their submission is saved in the database, but they cannot view their code later when they have closed the page. A feature where they can view their previous results would be a great addition to view their progress.
This would require us to implement new API endpoints and also create a new view with the Monaco editor.
Tracked in issue: #163
Bugs
Fix overflow for Roast submission messagesF
There is an issue where the scrollbar doesn’t appear when the Roast submission messages overflow. This happens when the user submits code with many errors and/or warnings.
Tracked in issue: #134
Register XHR request callback gets interrupted by Google ChromeF
With a cold browser cache the XHR request callback gets interrupted by Google Chrome. This is probably due to the 6 max TCP connections limit in the web browser. This bug only occurs for Google Chrome with a cold cache, if the cache is warm there is no issues.
The interrupt will stop Mithril.js from redirecting to the front page upon a successful registration. The user registration is correctly registered by the backend and the user is still able to login with the newly created account.
Tracked in issue: #226
Requirement for full name differs with the backendF
Upon registration the user is required to fill in their full name, even though it’s not a requirement in the backend. Several views in the frontend utilizes the full name and they should be updated to show the username if there is not full name defined.
The registration requirement for a full name can be removed after the views has been updated.
Tracked in issue: #210
Setup and install manual
The setup and install manual is attached below, you can also view it at:
https://github.com/LuleaUniversityOfTechnology/2018-project-roaster/blob/master/doc/guide/install.md.
The source code repository can be found here:
https://github.com/LuleaUniversityOfTechnology/2018-project-roaster.
Warnings and errors for Roast submissions.↩︎
Continuous Integration, Continuous Deployment↩︎
Node Package Manager↩︎
Software as a Service.↩︎
Model View Controller.↩︎
Document Object Model.↩︎
Explained below in↩︎
Explained below in .↩︎
Create, Read, Update, Delete↩︎
The cookie is always sent for every request by the web browser.↩︎
\(364.815906\) ms precisely on one of the developers slow laptop.↩︎
Shared global encryption key.↩︎
Using PostgreSQL’s
byteadata type.↩︎The output size of SHA-512.↩︎
National Institute of Standards and Technology in the US.↩︎
Two Factor Authentication↩︎